
동적 메모리 할당

동적 메모리 할당기는 heap이라고 하는 프로세스의 가상메모리 영역을 관리한다.
시스템마다 다르지만 일반적으로 stack은 낮은 영역으로, heap은 높은 영역으로 주소를 확장한다.
kernel은 변수 brk를 사용하여 heap의 꼭대기를 가리킨다.
프로그램을 실제로 실행시키기 전에 자료 구조의 크기를 알 수 없는 경우가 많다. 따라서 임의의 큰 값 할당하기보다는 런타임 중 필요한 크기를 알게 되었을 때 할당해 주는 동적할당 방식이 매우 효율적이다.
할당기의 요구사항과 목표
요구사항
- 임의의 요청 순서 처리하기
- 요청에 즉시 응답하기
- 힙만 사용하기
- 블록 정렬하기
- 할당된 블록을 수정하지 않기
목표
- 처리량 극대화하기
- 메모리 이용도를 최대화하기
할당기를 구현하기 전에 알아둬야 할 점
malloc이 반환하는 주소는 어떤 비트모드에서 동작하도록 컴파일되었는지에 따라 다르다.
32비트 모드(gcc -m32)일 경우에는 주소가 항상 8의 배수인 블록을 리턴한다.
64비트 모드(기본설정)에서는 항상 주소가 16 배수이다.
아래 내용은 32비트 모드에서 동작하는 동적할당기임을 명시하자.
Implicit Allocator

implicit 한 방법은 가용 블록 외에도 할당된 블록까지 포함하여 탐색을 진행하는 방식이다.
모든 방식을 탐색하기 때문에 효율이 많이 떨어지지만 차례대로 검사하는 first-fit방식보다는 마지막 검사한 블록을 시작으로 하여 검사하는 next-fit방식을 사용하여 성능을 약간 높일 수 있다.
Malloc 구현에 필요한 매크로
/* Basic constants and macros */
#define WSIZE 4 /* Word 그리고 header/footer의 크기는 4byte */
#define DSIZE 8 /* Double word size (bytes) */
#define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */
#define MAX(x,y) ((x) > (y) ? (x) : (y))CHUNKSIZE는 2^12로 4KB라는 것을 알 수 있다. 한 번 extend를 요청하면 4KB만큼의 heap 영역이 늘어나게 된다.
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc))
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))PACK은 가장 하위 비트를 바꾸는 연산으로 할당하거나 해제할 때 사용된다.
블록의 header와 footer에 값은 최상위 비트가 부호를 의미하지 않고 유의미한 값을 가지므로 unsigned int로 접근해야 한다.
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)Header에서 size를 얻기 위해서는 GET을 통해 header 정보를 얻어오고 ~0x7과 &연산을 통해 하위 비트 3개를 제거하여 얻는다.
크기는 항상 8(1000(2))의 배수이기 때문에 하위 3개의 bit는 block의 크기에 대해서는 무의미한 정보라는 것을 명심하자.
할당된 블록인지 아닌지는 하위 1개의 bit에 저장되어 있기 때문에 0x1과 &연산을 통해 할당 유무를 알 수 있다.
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
bp(그림에서는 heap_listp가 bp)는 Header의 앞을 가리키는 포인터이다. 따라서 Header에 접근하기 위해서는 한 블록의 크기를 빼주면 된다.
bp를 이용해 Footer에 접근하기 위해서는 Header에 저장된 size값을 이용하면 된다. 주의해야 할 점은 size는 payload뿐만 아니라 header, footer를 모두 포함한 크기이므로 bp에서 size만큼 더하고 DSIZE(header와 footer의 크기) 만큼 빼줘야 한다는 것이다.
위 동작 방식을 이해하면 NEXT_BLKP와 PREV_BLKP 코드에 대해 쉽게 이해할 수 있다.
init

heap을 생성하면 가장 앞에는 사용하지 않는 padding block이 온다. 그 이후에는 header와 footer로 구성된 Prologue block이 온다.
Prologue block들은 초기화 과정에서 생성되며 절대로 반환되지 않는다. 힙은 Epliogue block으로 끝나며 크기가 0으로 헤더 만드로 할당된 블록이다. 이런 Prologue block과 Epliogue block을 이용하여 heap에 접근하는 동안 가장자리 조건을 없애줄 수 있다.
Prologue block을 2개 할당하는 이유는 이를 확인함으로써 heap이 잘 구현되었다는 것을 확인하기 때문이다.
int mm_init(void)
{
/* Create the initial empty heap */
if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1) return -1;
PUT(heap_listp, 0); /* Alignmnet padding */
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); /* Prologue header */
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); /* Prologue footer */
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); /* Epilogue header */
/* Extend the empty heap with a free block of CHUNKSIZE bytes */
if (extend_heap(CHUNKSIZE/WSIZE) == NULL) return -1;
return 0;
}따라서 처음에 mem_sbrk 함수를 이용하여 4개의 블록을 채울 수 있는 공간이 있는지 확인한다.
다음에는 padding block, Prologue block, Epliogue block을 할당해 주고 heap을 CHUNKSIZE/WSIZE 만큼 연장해 주면 된다.
malloc
void *mm_malloc(size_t size)
{
size_t asize; /* Adjusted block size */
size_t extendsize; /* Amount to extend heap if no fit */
char *bp;
/* Ignore spurious requests */
if (size == 0) return NULL;
/* Adjust block size to include overhead and alignment reqs. */
if (size <= DSIZE) asize = 2*DSIZE;
else asize = DSIZE * ((size + (DSIZE) + (DSIZE -1)) / DSIZE);
/* Search the free list for a fit */
if ((bp = find_fit(asize))!=NULL){
place(bp,asize);
return bp;
}
/* No fit found. Get more memory and place the block */
extendsize = MAX(asize,CHUNKSIZE);
if ((bp = extend_heap(extendsize/WSIZE))==NULL) return NULL;
place(bp,asize);
return bp;
}우리는 32bit 모드를 사용하기 때문에 항상 8(DSIZE)의 배수인 블록을 리턴해야 한다. 따라서 size가 들어올 경우 8의 배수로 바꿔줘야 한다.
size가 8보다 작을 경우 Header와 Footer도 포함해야 하기 때문에 8이 아닌 16만큼 할당해줘야 한다.
size가 16보다 클 경우에는 조금 복잡해진다.
asize = DSIZE * ((size + (DSIZE) + (DSIZE -1)) / DSIZE);size + (DSIZE)는 size에 Header와 Footer가 요구하는 공간의 합이므로 이해가 된다. 하지만 왜 여기에 (DSIZE-1)을 더해주는 것일까?
size+(DSIZE)가 13일 경우 asize는 16이 할당되어야 한다. 8을 넘지 않는 최대 정수 7을 더하고 8로 나눈 뒤 다시 8을 곱해주면 16이 나오게 된다. 즉, 위 공식은 size + (DSIZE) 보다 큰 8의 배수 중 가장 작은 수를 구하는 공식이다.
extend_heap
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE;
if((long)(bp = mem_sbrk(size))==-1) return NULL;
/* Initialize free block header/footer and the epilogue header */
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0,1)); /* New eiplogue header */
/* Coalesce if the previous block was free */
return coalesce(bp);
}위 코드 블록의 7번째 줄에서 size를 짝수로 만들고 WSIZE 만큼 곱해주고 있다.
나는 왜 굳이 짝수로 보장이 된 words를 다시 짝수로 만들고 WSIZE를 나누어서 들어온 값에 WSIZE를 다시 곱하는지 의문이 들었다.
코치님에게 여쭤본 결과 큰 프로젝트에서는 개개인이 모든 프로그램의 흐름을 모르기 때문에 함수가 어떤 역할을 하는지 드러나도록 코딩을 하는 경우가 있다고 하셨다. extend_heap이 짝수*WSIZE만큼 메모리를 확장한다는 것을 보여주기 위해 반복되는 코드를 넣은 것 같다.
extend_heap의 코드를 자세히 뜯어보면 init에서 구현한 epilogue의 역할에 대해 알 수 있다.

초기에 init을 하면 위와 같은 heap이 생성되게 된다.
여기서 4개의 블록을 연장하는 과정을 살펴보자
if((long)(bp = mem_sbrk(size))==-1) return NULL;
함수 mem_sbrk(size)를 실행하면 bp는 확장 전에 memory의 끝 주소값을 가지게 된다.
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */
bp를 기준으로 Header와 Footer에 값을 넣어준다
PUT(HDRP(NEXT_BLKP(bp)), PACK(0,1)); /* New eiplogue header */
bp의 다음 블록의 Header에 eiplogue block을 넣어준다.
이 과정을 통해 eiplogue block이 새로운 block을 할당할 때 추가되지 않은 메모리에 접근하지 못하게 도와주는 것을 알 수 있다.
coalesce
통합하는 과정을 4개로 구분할 수 있다.

if(prev_alloc && next_alloc){ /* Case 1 */
return bp;
}해제되는 블록과 인접한 블록 모두 할당되어 있는 경우로 딱히 처리할 게 없다.

else if (prev_alloc && !next_alloc){ /* Case 2 */
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}뒤에만 있는 블록이 가용블록인 경우 두 가용블록을 합쳐주어야 한다.
Header와 Footer 모두 할당 해제해 주고 size를 뒤에 있는 블록의 크기만큼 늘려준다.
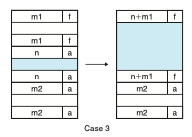
else if(!prev_alloc && next_alloc){ /* Case 3 */
size += GET(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size,0));
bp = PREV_BLKP(bp);
}앞에만 가용블록이 있는 경우에도 합치고 블록의 할당을 해제해야 한다. 다른 점이 있다면 이전 블록의 bp값을 리턴해야 한다는 것이다.

else /* Case 4 */
{
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}마지막으로 4번째의 경우는 양옆 모두 가용블록인 경우이다.
이 경우는 경우 2와 3을 합친 것으로 앞 뒤 블록의 크기를 합치고 이전 블록의 bp값을 리턴해주면 된다.
find_fit
static void * find_fit(size_t asize){
void *bp;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp)) {
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp)))) {
return bp;
}
}
return NULL;
}find_fit은 first_fit 방식으로 구현하였다. malloc을 할 때마다 메모리의 시작주소부터 끝 주소까지 크기에 맞는 가용블록을 찾는다. for문을 도는 조건을 GET_SIZE(HDRP(bp))로 두었기 때문에 epilogue block을 만났을 때 종료하게 된다.
place
static void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp));
if ((csize - asize) >= (2*DSIZE)) {
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize-asize, 0));
PUT(FTRP(bp), PACK(csize-asize, 0));
}
else {
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}first-fit 방식을 통해 충분한 크기를 가진 가용메모리의 bp값을 받아왔다.
가용메모리의 크기를 csize라고 할 때, 가용메모리를 사용하고 남은 메모리는 csize - asize라고 할 수 있다.
2*DSIZE는 블록이 할당될 수 있는 최소단위이기 때문에 csize-asize일 경우에는 정상적으로 할당한다.
하지만 그렇지 않은 경우 남은 공간(csize-asize)은 사용되지 못하는 쓰레기 값이 되기 때문에 그냥 csize만큼 공간을 할당해 준다.
free
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size,0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}block point를 받아와 값을 해제한다.
PACK 매크로를 이용해 Header와 Footer의 할당을 해제하고 coalesce 함수를 이용하여 앞 뒤의 가용블록들이 있다면 합쳐준다.
realloc
void *mm_realloc(void *ptr, size_t size)
{
size_t oldsize;
void *newptr;
/* If size == 0 then this is just free, and we return NULL. */
if(size == 0) {
mm_free(ptr);
return 0;
}
/* If oldptr is NULL, then this is just malloc. */
if(ptr == NULL) return mm_malloc(size);
newptr = mm_malloc(size);
/* If realloc() fails the original block is left untouched */
if(!newptr) return 0;
/* Copy the old data. */
oldsize = GET_SIZE(HDRP(ptr));
if(size < oldsize) oldsize = size;
memcpy(newptr, ptr, oldsize);
/* Free the old block. */
mm_free(ptr);
return newptr;
}realloc 함수는 기존에 할당된 메모리를 재할당 하는 함수로 사이즈는 바뀌지만 안에 내용은 유지해야 한다.
하지만 realloc 함수는 input값에 따라서 다른 역할을 한다.
만약 할당하는 size가 0일 경우 free(bp)와 같은 의미를 갖는다.
또, ptr 값이 NULL이라면 기존에 할당된 메모리 주소가 없기 때문에 malloc(size)와 같은 의미를 갖는다.
위 내용에 대해 예외 처리를 해주고 realloc을 구현하면 된다.
realloc 코드는 해당 과제에서 짜여 있었다.
해석하자면 먼저 size만큼 새로운 메모리 주소에 메모리에 값을 할당하고 기존의 값을 옮긴다.
그다음에 기존의 값을 해제한다.
기존의 메모리 주소의 사이즈를 변경하는 방법이 아니라 새로운 메모리 주소에 크기를 할당하고 값을 붙여 넣는다는 방식이라는 것을 유의하자.
속도

util은 메모리 시스템의 이용률을 나타내고 thru는 메모리의 대역폭을 나타낸다.
first-fit 방식은 할당을 할 때마다 메모리의 시작 주소부터 가용블록을 찾는다. 이 방식을 사용하면 메모리의 앞쪽에 할당 블록이 몰리게 되고 시작 주소부터 검색하기 때문에 할당 주소를 찾는데 많은 overhead가 발생한다.
util : 메모리 시스템의 이용률을 나타낸다. 이는 시스템이 메모리를 얼마나 빈번하게 사용하고 있는지를 나타내며, 이용률이 높을수록 시스템이 메모리를 더 빈번하게 사용하고 있다는 것을 의미한다.
thru : 메모리 대역폭을 나타낸다. 이는 시스템이 단위 사간당 메모리에서 전송할 수 있는 데이터 양을 나태 내며, 대역폭이 높을수록 시스템이 데이터를 더 빠르게 전송할 수 있다는 것을 의미한다.
속도개선 : next-fit
next-fit은 first-fit 방식과 다르게 검색이 종료된 주소부터 가용블록을 찾는다.
static char * rover;종료된 주소를 저장하는 전역변수 rover를 선언한다.
//init()
heap_listp+=(2*WSIZE);
rover = heap_listp;init()이 실행될 때 heap_listp의 값을 초기 rover값으로 할당한다.
static void * find_fit(size_t asize){
/* Search from the rover to the end of list */
for (char* bp =rover ; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
return rover = bp;
/* search from start of list to old rover */
for (char* bp = heap_listp; bp < rover; bp = NEXT_BLKP(bp))
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
return rover = bp;
return NULL;
}검색이 일어날 때마다 rover를 갱신해 주면 된다.
이외에도 coalesce 함수도 수정해줘야 한다.

위 같이 bp에 대한 할당이 끝난 상황이 있다고 가정하자.
bp를 할당하자마자 해제할 경우 각각의 변수들의 위치는 다음과 같다.
rover가 접근하면 안 되는 영역에 있는 것을 볼 수 있다.

따라서 할당하자마자 해제하는 경우 rover를 bp로 옮겨줘야 한다.
//coalesce
if ((rover > (char *)bp)&& (rover < NEXT_BLKP(bp))) rover = bp;
따라서 데이터 통합 후에 rover가 bp보다 작다면 rover에 bp를 할당하여 올바른 주소에만 접근 가능하도록 코드를 추가해야 한다.
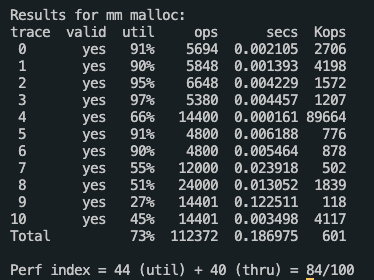
성능이 많이 향상된 것을 볼 수 있다.
Explicit Allocator

Implicit Allocator는 구현이 쉽지만 블록 할당 시간이 전체 힙의 블록 수에 비례한다는 단점이 존재한다.
Explicit Allocator는 가용 블록만을 모아놓은 이중연결 리스트를 이용하여 Implicit Allocator의 단점을 보완한다.
생성되는 블록의 크기는 최소 16byte이고 Header와 Footer를 제외하면 최소 8byte 크기의 공간이 남게 된다. 가용 블록인 경우 이 공간에 이전 리스트 주소와 다음 리스트의 주소를 저장하여 연결리스트의 요소가 될 수 있도록 한다. 이 주소들은 블록에 값이 할당되면 없어진다.
Implicit Allocator를 만들었다면 연결리스트와 가용블록이 생성되는 부분만 일부 수정해 주면 된다.
매크로
#define PRED(bp) ((char *)(bp))
#define SUCC(bp) ((char *)(bp) + WSIZE)이중연결 리스트에서 이전 요소를 가리키는 PRED와 다음 요소를 가리키는 SUCC를 만들었다.
init
int mm_init(void)
{
/* Create the initial empty heap */
if ((heap_listp = mem_sbrk(6*WSIZE)) == (void *)-1) return -1;
PUT(heap_listp, 0); /* Alignmnet padding */
PUT(heap_listp + (1*WSIZE), PACK(2*DSIZE, 1)); /* Prologue header */
PUT(heap_listp + (2*WSIZE), NULL); /* PRED */
PUT(heap_listp + (3*WSIZE), NULL); /* SUCC */
PUT(heap_listp + (4*WSIZE), PACK(2*DSIZE, 1)); /* Prologue footer */
PUT(heap_listp + (5*WSIZE), PACK(0, 1)); /* Epilogue header */
heap_listp+=(2*WSIZE);
root = heap_listp;
PUT(SUCC(root),PRED(root));
/* Extend the empty heap with a free block of CHUNKSIZE bytes */
if (extend_heap(CHUNKSIZE/WSIZE) == NULL) return -1;
return 0;
}명시적 할당기 방식으로 구현할 경우 초기화에 총 6개의 블록이 필요하다.

implicit 한 방식처럼 4개만 사용할 수 있지만 6개를 사용하여 root를 다른 요소들과 같은 형식으로 만들어 코드를 더 간결하게 짤 수 있다.

PUT(SUCC(root),PRED(root)) 코드를 통해 root의 SUCC에 root 주소를 넣어주었다.
이렇게 처리를 해야 코드를 간결하게 짤 수 있다.

만약 아무 처리도 안 해주고 SUCC(root)에도 NULL을 넣는다면 자신의 이전노드 혹은 다음노드가 없는 경우 예외 처리를 해주어야 한다.
- 루트노드만 있을 때 삽입을 하는 경우
- 루트노드를 제외하고 마지막 남은 노드를 삭제하는 경우
PUT(SUCC(root),PRED(root))를 한다면 연결리스트는 다음처럼 표현 할 수 있다.

이렇게 전처리를 해준다면 삽입 또는 삭제되는 노드에게 이전노드와 다음노드 모두 존재하기 때문에 예외처리를 해줄 필요가 없게 된다.
void add_list(char *bp){
PUT(RED(GET(SUCC(root))), bp);
PUT(SUCC(bp), GET(SUCC(root)));
PUT(SUCC(root), bp);
PUT(PRED(bp), root);
}
void del_list(char *bp){
PUT(SUCC(GET(PRED(bp))), GET(SUCC(bp)));
PUT(PRED(GET(SUCC(bp))), GET(PRED(bp)));
}
extend_heap
//extend_heap
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
PUT(PRED(bp), NULL); /* PRED */
PUT(SUCC(bp), NULL); /* SUCC */
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0,1)); /* New eiplogue header */heap을 늘리는 경우 가용블록이 생성된다. Explicit Allocator의 경우 PRED와 SUCC를 넣어주어야 한다.
coalesce
if(prev_alloc && next_alloc){ /* Case 1 */
add_list(bp);
}
else if (prev_alloc && !next_alloc){ /* Case 2 */
del_list(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
add_list(bp);
}
else if(!prev_alloc && next_alloc){ /* Case 3 */
size += GET(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp),PACK(size,0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size,0));
bp = PREV_BLKP(bp);
}
else /* Case 4 */
{
del_list(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}coalesce는 가용블록이 생성되었을 때 병합하는 부분이다.
다음 블록과 병합될 경우 bp는 앞에 있는 블록의 주소가 되기 때문에 연결리스트에 존재하는 다음 블록에 대한 노드를 삭제해야 한다.
이전 블록과 병합될 경우 이미 이전 블록이 연결리스트에 존재하기 때문에 따로 bp를 삽입하지 않아도 된다.
이전 블록과 병합되지 않는 경우 bp를 리스트에 넣어주어야 한다.
find_fit
static void * find_fit(size_t asize)
{
/* Search from the rover to the end of list */
for (char *cur = GET(SUCC(root)); !GET_ALLOC(HDRP(cur)); cur = GET(SUCC(cur)))
if (asize <= GET_SIZE(HDRP(cur)))
return cur;
return NULL;
}root노드의 다음 노드부터가 가용블록이므로 GET(SUCC(root))부터 탐색을 시작해야 한다.
연결리스트에 끝은 root노드를 가리키고 있다. root노드는 유일하게 연결리스트에서 존재하는 할당 블록이기 때문에 할당된 블록을 만나면 탐색을 종료하도록 바꾸었다.
place
static void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp));
del_list(bp);
if ((csize - asize) >= (2*DSIZE)) {
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize-asize, 0));
PUT(FTRP(bp), PACK(csize-asize, 0));
coalesce(bp);
}
else {
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}place는 find_fit을 통해 찾은 가용블록에 할당해 주는 함수이다. 따라서 연결리스트에 있는 bp의 정보를 삭제해주어야 한다.
속도

속도는 Implicit Allocator의 next-fit방식과 유사하게 나왔다.
더 빠른 속도가 나올줄 알았는데 그건 아니었다.
포스팅을 마치며
크래프톤 정글의 6주차 과정 malloc 구현을 끝냈다. 우리가 사용하던 malloc 함수가 어떻게 동작하는지 완벽하게 이해했다.
seglist까지 구현하고 싶었으나 시간이 없어서 아쉬웠다.
또, 매우 비효율적으로 짠 realloc도 시간이 된다면 효율적으로 짜보고 싶다.
이번에 배운 내용이 PintOS를 할 때 유용하게 쓰였으면 좋겠다.
GitHub - YongHyunKing/malloc-lab: malloc 구현
malloc 구현. Contribute to YongHyunKing/malloc-lab development by creating an account on GitHub.
github.com